


前言
原文:https://www.theregister.com/2021/08/10/ai_master_face/
译者编辑:suke
想法来源
所谓
“主脸”的想法,即由机器学习算法生成的一组假图像,通过冒充人来破解面部生物识别系统,上周成为引人注目的头条新闻。但仔细研究该研究会发现明显的弱点,使其不太可能在现实世界中发挥作用。
相关文献
本月早些时候在 arXiv 上发布的这篇论文解释说:
“一张主脸是一张人脸图像,它通过了大部分人口的面部身份验证。”“这些面孔可以用来冒充任何用户,而且成功的可能性很高,而无需访问任何用户信息。”
实验
特拉维夫大学的三位学者继续说,他们建立了一个模型,该模型生成了 9 张主脸,能够代表 40% 的人口,
绕过了“三个领先的深度人脸识别系统”。乍一看,这似乎令人印象深刻,而且这些声明在需要面部识别的应用程序中构成了明显的安全风险。
实验细节
首先,该团队使用Nvidia 的StyleGAN系统来创建假脸的逼真图像。每个假输出都与 Labeled Faces in the Wild (LFW) 数据集中代表的 5,749 个不同人的一张真实照片进行比较。单独的分类器算法确定与数据集中的真实人脸相比,人工智能生成的假人脸的相似程度。
分类器相似度得分高的图像被保留,其他图像被丢弃。这些分数用于训练进化算法,以使用 StyleGAN 创建越来越多看起来像数据集中的人的恶搞面孔。
随着时间的推移,研究人员能够在数据集中找到一组代表尽可能多的图像的主人脸。简而言之,他们只能用 9 张图像来代表 Labeled Faces in the Wild 数据集中 5,749 个不同人的 40%。
接下来,他们使用这些主人脸来欺骗三种人脸不同的人脸识别模型:Dlib、FaceNet 和 SphereFace。这些系统在对 LFW 数据集上测试的最佳人脸匹配算法进行基准测试的竞赛中排名最高。
然而,快速浏览能够绕过这三个模型中的每一个的得分最高的主面孔,就会发现研究存在明显的局限性。它们几乎都是白发、眼镜和胡须的老年白人男性的假照片。如果这些相同类型的图像能够代表大量的 LFW 数据集,那么该数据集肯定存在一些缺。

垃圾进,垃圾出
发布在托管数据集的网站上的免责声明证实了这一点:
“许多群体在 LFW 中没有得到很好的代表。例如,孩子很少,没有婴儿,80岁以上的人很少,女性比例相对较小。此外,许多种族的代表性非常低或根本没有。”
九个主脸的分数反映了 LFW数据集的局限性。女性、肤色较深和较年轻的面孔排名较低,并且不太可能绕过测试的三个模型。
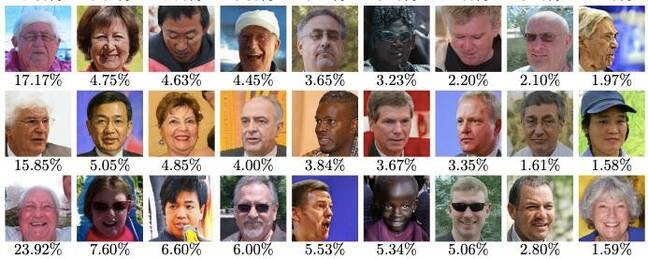
“虽然理论上 LFW 可用于评估某些亚组的表现,但该数据库的设计目的是没有足够的数据来得出关于亚组的强有力的统计结论。简单地说,LFW 不够大,无法证明某个特定软件已经过彻底测试,”根据LFW 网站上列出的另一份免责声明。
尽管能够模拟大部分人脸以解锁人脸识别系统的主脸的想法很有趣,但这里的研究只是使用有缺陷的数据训练和测试机器学习模型的另一个案例。正如他们所说,垃圾进,垃圾出。
LFW数据集缺乏多样性,因此计算机生成的主人脸更有可能覆盖该数据集的更大比例。这些图像不太可能在现实世界中也能正常工作。
并且没有真实世界的测试
“LFW 确实受到其官方网站中描述的局限性的影响,但尽管存在这些局限性,LFW 仍然是学术文献中广泛使用的数据集,用于评估人脸识别方法,”该论文的合著者兼研究员 Tomer Friedlander 特拉维夫大学电气工程学院告诉 The Register。
“我们的论文提出了人脸识别系统可能存在的漏洞,攻击者可以利用该漏洞。因此,人脸识别方法的开发者和用户都应该考虑到这一点。我们还没有针对现实生活中使用的商业人脸识别系统测试我们的方法,所以我们不能参考现实生活中的系统。”
他说,有可能使模型适应更好的数据集,这些数据集更加多样化,以尝试和欺骗现实世界中的系统。“我们有兴趣进一步探索使用我们的方法生成的主面部的可能性,以帮助保护现有的面部识别系统免受此类攻击。我们将其留作未来的研究。”
不要被那些声称这些大师面孔可以闯入“超过 40% 的面部 ID 身份验证系统”或它们“非常成功”的骇人听闻的头条新闻所迷惑。几乎没有证据支持这些说法。
弗里德兰德告诉我们,该论文已被今年 12 月举行的IEEE 自动人脸和手势识别国际会议接受。
评论区